
k-平均法:データの自動分類

デジタル化を知りたい
先生、「k-平均法」ってよく聞くんですけど、難しそうでよくわからないんです。簡単に教えてもらえますか?

デジタル化研究家
いいかい?k-平均法は、ものごとをいくつかの仲間に分ける方法の一つなんだ。たとえば、生徒全員のテストの点数をk-平均法で3つのグループに分けるとすると、似た点数の生徒たちが3つのグループに分けられる。これがk-平均法だよ。
デジタル化を知りたい
なるほど。似たもの同士をグループ分けするんですね。でも、どうやってグループを決めるんでしょうか?
デジタル化研究家
まず、コンピュータが適当にグループ分けをする。次に、各グループの真ん中の値(平均値)を求める。そして、それぞれの生徒を、一番近い平均値のグループに割り当て直すんだ。これを繰り返すと、だんだんグループ分けが安定してくる。これがk-平均法の仕組みだよ。
k-平均法とは。
データの集まりをいくつかのグループに分ける方法の一つに、階層を作らないやり方があります。その中で、『k平均法』と呼ばれる方法があります。これは、あらかじめいくつのグループに分けるかを決めて(これをk個のグループと呼びます)、データ同士の距離を計算し、グループ分けを行います。どのデータがどのグループに属するかを決めるときには、それぞれのグループに属するデータ同士の距離の平均値を計算します。この平均値を使って、よりデータ同士の距離が近くなるようにグループ分けを調整していきます。そして、最終的にk個のグループにデータが分けられます。
はじめに

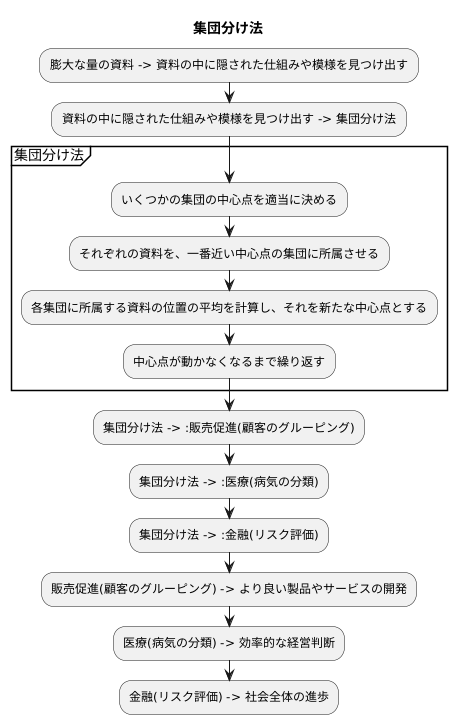
近ごろ、あらゆる分野で膨大な量の資料が作られています。これらの資料を役立てるには、資料の中に隠された仕組みや模様を見つけ出すことが大切です。多くの資料を自動的にグループ分けする手法の一つに、集団分け法があります。この手法は、資料の山をいくつかの集団に分類することで、資料に隠された情報を見つけ出すのに役立ちます。
集団分け法は、どのようにして集団を作るのでしょうか。まず、いくつかの集団の中心点を適当に決めます。次に、それぞれの資料を、一番近い中心点の集団に所属させます。そして、各集団に所属する資料の位置の平均を計算し、それを新たな中心点とします。この作業を、中心点が動かなくなるまで繰り返すことで、最終的な集団分けが完了します。
この手法は、扱う資料の種類に左右されず、様々な分野で使われています。例えば、販売促進の分野では、顧客を購買行動の特徴に基づいてグループ分けし、それぞれのグループに合わせた販売戦略を立てるのに役立ちます。医療の分野では、患者の症状や検査結果に基づいて病気を分類し、適切な治療法を選択するのに役立ちます。また、金融の分野では、顧客の信用度に基づいてリスクを評価し、融資の可否を判断するのに役立ちます。
このように、集団分け法は、資料に基づいた判断を助ける上で重要な役割を担っています。大量の資料の中から意味のある情報を引き出すことで、より良い製品やサービスの開発、効率的な経営判断、そして社会全体の進歩に貢献することができます。資料の有効活用は、これからの社会をより良くしていくための鍵となるでしょう。
手法の仕組み

この手法は、ものをいくつかの集まりに分ける方法で、「K平均法」と呼ばれています。この手法では、まず初めに、分けたいものの集まりから、いくつかのものを適当に選び出します。選び出すものの数は、最初に決めておきます。たとえば、3つの集まりに分けたい場合は、3つのものを選び出します。この選び出したものを「中心」と呼びます。
次に、分けたいもののそれぞれと、中心との間の隔たりを測ります。そして、それぞれのものが、どの「中心」に一番近いかを調べます。一番近い中心と同じ集まりに、そのものを分けます。これで、すべてのものが、どれかの集まりに分けられます。
すべてのものが集まりに分けられたら、今度は、各集まりに含まれるものの平均の位置を計算します。この平均の位置が、新しい「中心」になります。
新しい中心が決まったら、また、分けたいもののそれぞれと、新しい中心との間の隔たりを測り、一番近い中心の集まりに、そのものを分け直します。これを繰り返していくと、中心の位置がほとんど動かなくなります。中心が動かなくなったら、そこで作業を止めます。こうして、最終的に、ものをいくつかの集まりに分けることができます。
この手法は、ものの散らばり具合を見て、似た特徴を持つものを同じ集まりにするため、ものの集まりの構造を分かりやすく図に表すのに役立ちます。
最適なグループ数

集まり分けの手法である「ケー平均法」では、いくつの集まりを作るかを決める必要があります。この集まりの数を「ケー」という値で表します。しかし、最適な「ケー」の値は、扱う情報の種類によって変わるため、適切な値を選ぶことが非常に大切です。「ケー」の値が小さすぎると、本来は異なる性質の情報が同じ集まりに分類されてしまうことがあります。例えば、犬と猫を同じ集まりにまとめてしまうようなイメージです。反対に、「ケー」の値が大きすぎると、似た性質の情報が別々の集まりに分けられてしまう可能性があります。例えば、様々な種類の犬をそれぞれ別の集まりに細かく分けてしまうようなイメージです。
では、最適な「ケー」の値はどうやって見つけるのでしょうか? いくつかの方法がありますが、代表的なのは「ひじ法」と「影絵分析」です。これらの方法は、集まりの中の情報の散らばり具合と、集まり同士の情報の違いを比べることで、最適な「ケー」の値を推測します。「ひじ法」は、様々な「ケー」の値で計算した結果をグラフに描き、グラフの線が折れ曲がる「ひじ」の部分を探すことで最適な「ケー」の値を見つけます。まるで腕を曲げたときのように、グラフの線が折れ曲がる部分がおおよそ最適な「ケー」の値を示しています。「影絵分析」は、それぞれの情報がどの程度自分の集まりに属しているかを数値で表し、その平均値から最適な「ケー」の値を判断します。どの情報も所属する集まりによく馴染んでいれば、その「ケー」の値は適切であると判断できます。
最適な「ケー」の値を見つけることは、情報を正しく分類するために非常に重要です。適切な「ケー」の値を選ぶことで、情報の性質をより正確に捉え、有益な知見を得ることができるようになります。
| ケー平均法とは | データをk個のクラスタに分類するアルゴリズム |
|---|---|
| kの値の重要性 |
|
| 最適なkの値の決定方法 |
|
利点と欠点

データの自動仕分けでよく使われる手法の一つである「集団分け法」について、その利点と欠点を詳しく見ていきましょう。集団分け法は、データをいくつかのまとまりに分ける方法で、その中でも「中心点を使う分け方」は計算の手間が少なく、大規模なデータにも対応できるという大きな利点があります。手軽に使えるため、多くの処理手順集や数式処理ソフトに組み込まれており、誰でも簡単に利用できる点も魅力です。
しかし、この手法にはいくつか注意点もあります。まず、最初の分け方の基準となる点の選び方によって、最終的な分け方の結果が変わってしまう可能性があります。まるで雪だるま式に誤差が大きくなるように、最初の小さな違いが最終的に大きな違いを生み出してしまうのです。また、極端に外れた値に影響されやすいという弱点もあります。一つの突出した値が全体の分け方に大きく影響してしまうため、データの中に特殊な値が含まれている場合は注意が必要です。さらに、この手法は丸い形のまとまりを作る傾向があります。そのため、実際には複雑な形のまとまりになっているデータを正しく分けられない場合があります。例えるなら、丸い型抜きで星型を切り抜こうとするようなもので、どうしても合わない部分が出てきてしまいます。
これらの欠点を補うために、「中心の値を使う分け方」や「改良型中心点を使う分け方」など、様々な改良版が考え出されています。これらの改良版は、最初の分け方の影響を減らしたり、極端な値の影響を抑えたりすることで、より正確な分け方を実現しています。より高度な分析を行う際には、これらの改良版も検討する価値があります。
| 手法 | 利点 | 欠点 | 改良版 |
|---|---|---|---|
| 中心点を使う分け方 |
|
|
|
様々な応用例

多くの分野で活用されている手法である、集団分けを用いる解析手法は、様々な場面で役立っています。この手法は、データの集まりを似ているもの同士でいくつかの集団に分類する方法です。この集団の数をあらかじめ決めておくことが特徴です。
例えば、販売促進活動に役立てる場面を考えてみましょう。この手法を使えば、顧客の購入履歴や顧客の持つ特徴といった情報をもとに、顧客をいくつかの集団に分類することができます。あるものが好きな人、よく買う人は似たような傾向を持つ別のものにも興味を持つ可能性が高い、という考えに基づき分類することで、それぞれの集団に合わせた効果的な販売戦略を立てることが可能になります。
画像を扱う場面でも、この手法は力を発揮します。画像を構成する小さな点の色や明るさを数値化し、それを手がかりにして画像を分類します。例えば、大量の画像データの中から、猫の画像だけを抽出したり、風景写真だけを選別したりといったことが可能になります。また、ある画像と似た画像を検索する際にも、この手法が利用されます。
普段と異なる出来事を発見する場面でも、この手法は役立ちます。まず、普段の様子を示すデータから、何が普通なのかを学習します。そして、その学習結果をもとに、新しいデータが普通の状態からどれくらい外れているかを調べます。もし、大きく外れている場合は、何か異常なことが起こっていると判断できます。例えば、工場の機械の稼働状況データから、故障の予兆を捉えるといったことに応用できます。
このように、集団分けを用いる解析手法は、データを扱う多くの分野で重要な道具として、幅広く活用されています。大量のデータから意味のある情報を引き出し、実用的な問題解決に役立てることができるのです。
| 活用分野 | 活用例 | 説明 |
|---|---|---|
| 販売促進 | 顧客のセグメンテーション | 顧客の購入履歴や属性に基づいて顧客をグループ分けし、それぞれのグループに最適な販売戦略を策定する。 |
| 画像処理 | 画像分類、類似画像検索 | 画像の色や明るさなどの特徴量に基づいて画像を分類したり、類似画像を検索したりする。 |
| 異常検知 | 機械の故障予兆検知 | 正常な状態を学習し、新しいデータが正常状態から逸脱している場合に異常を検知する。 |
まとめ

集積データを適切に分類することは、データの持つ意味を理解し、新たな発見につなげる上で欠かせない作業です。そのための有効な手段の一つとして、階層分け平均法があります。この方法は、大量のデータを限られた数の集団に効率よく分類する強力な手法であり、その簡潔さと処理の速さから、様々な分野で活用されています。
階層分け平均法の基本的な考え方は、データを似ているもの同士でまとめていくというものです。データ間の類似度を測る指標に基づいて、あらかじめ定めた数の集団にデータを割り当てていきます。この時、各集団の中心点となる代表値を計算し、各データと代表値との距離を基に、所属する集団を更新していきます。この操作を繰り返すことで、最終的に各集団内のデータができるだけ均質になるように分類されます。
階層分け平均法を使う上で重要なのが、集団の数を適切に決めることです。集団の数が少なすぎると、異なる性質のデータが同じ集団にまとめられてしまう可能性があり、逆に多すぎると、わずかな違いでデータが細かく分類されすぎてしまう可能性があります。最適な集団の数は、データの性質や分析の目的に合わせて慎重に検討する必要があります。また、初期の代表値の設定によって結果が変わるという性質も理解しておく必要があります。異なる初期値で複数回分析を行い、結果を比較することで、より安定した分類結果を得ることができます。
階層分け平均法には、初期値依存性や最適な集団数の決定といった課題も存在しますが、改良された手法や適切な設定を用いることで、より精度の高い分類を行うことができます。データの背後にある構造を明らかにし、新たな知見を得るためのツールとして、階層分け平均法はデータを取り扱う人にとって必須の知識と言えるでしょう。今後、データの量と複雑さが増していく中で、階層分け平均法とその改良手法はますます重要な役割を担っていくと考えられます。
| 手法 | 階層分け平均法 |
|---|---|
| 目的 | 大量データを限られた数の集団に分類 |
| 考え方 | 類似するデータ同士をまとめていく |
| 手順 | 1. データ間の類似度を測る指標に基づき、データをあらかじめ定めた数の集団に割り当てる。 2. 各集団の代表値を計算する。 3. 各データと代表値との距離を基に、所属する集団を更新する。 4. 3の操作を繰り返し、各集団内のデータができるだけ均質になるように分類する。 |
| ポイント | * 集団の数を適切に決める * 初期の代表値の設定によって結果が変わるため、異なる初期値で複数回分析を行い結果を比較する |
| 課題 | 初期値依存性、最適な集団数の決定 |
| 解決策 | 改良された手法や適切な設定を用いる |