
自己符号化器:データの本質を探る

デジタル化を知りたい
先生、『自動符号化器』って最近よく聞くんですけど、一体どんなものなんですか?

デジタル化研究家
そうだね。『自動符号化器』は、データを圧縮して、また元の形に戻せるように学習する仕組みだよ。たとえば、たくさんの絵を、少ない情報で表現して、また元の絵を再現できるようにするようなものだね。
デジタル化を知りたい
少ない情報で表現するっていうのは、どういうことですか?
デジタル化研究家
絵の特徴を捉えた、より少ないデータに変換するということだよ。たとえば、顔の絵だったら、目や鼻、口の位置や形といった特徴を数値化して、少ないデータで表現するんだ。そして、その少ないデータから元の絵を復元できるように学習していくんだよ。
AutoEncoderとは。
コンピュータ技術を使った変化(DX)で出てくる言葉、「自動符号化器」について説明します。これは、人間の脳の仕組みをまねたコンピュータの学習方法の一つで、特に答えを教えずにコンピュータ自身に学習させる方法で使われています。
自己符号化器とは

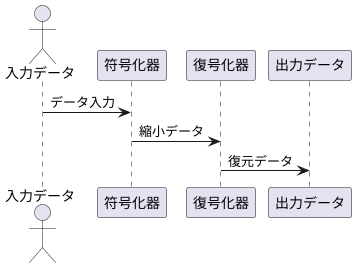
自己符号化器とは、人工知能の分野で用いられる、データを学習し、その本質的な特徴を捉える技術です。まるで職人が、様々な木材の中から、家具に適した材料を見分けるように、自己符号化器はデータの中から重要な特徴を抽出します。具体的には、入力されたデータを一度圧縮し、その後、元のデータにできるだけ近い形で復元する過程を学習します。この圧縮と復元の過程を繰り返すことで、データの本質的な特徴を捉える能力を獲得します。
自己符号化器の仕組みは、入力層、隠れ層、出力層の三層構造を持つニューラルネットワークで表現できます。入力層に入力されたデータは、隠れ層で圧縮され、より少ない次元の特徴量に変換されます。この隠れ層は、入力データの本質的な特徴を表現する部分であり、「符号」とも呼ばれます。その後、出力層では、隠れ層の符号から元のデータの復元を試みます。学習の過程では、入力データと復元データの差が最小になるように、ニューラルネットワークの各層の結合の強さを調整していきます。
自己符号化器は、データの次元削減、ノイズ除去、異常検知など、様々な用途に利用できます。例えば、高解像度の画像データは、そのままでは処理に時間がかかりますが、自己符号化器を用いて次元を削減することで、処理速度を向上させることができます。また、ノイズの多いデータからノイズを除去し、本来のデータを取り出すことも可能です。さらに、通常のデータとは異なる特徴を持つ異常データを検知するのにも役立ちます。
自己符号化器は、データの本質的な特徴を学習し、様々なタスクに利用できる強力な技術です。今後、さらに多くの分野での活用が期待されています。
仕組みと働き

自己符号化器は、まるで写し絵のような仕組みで働きます。まず、入力されたデータは、一度より小さな形に変換されます。これは、絵の具で描いた絵を一度濃い絵の具でなぞって、輪郭だけを抜き出すような作業です。この小さな形に変換する部分を符号化器と呼びます。次に、この小さくなったデータをもとに、元のデータと同じ形になるように復元します。これは、抜き出した輪郭だけをもとに、元の絵を再現するような作業です。この元の形に戻す部分を復号化器と呼びます。
この一連の変換、つまり小さくする処理と元に戻す処理を繰り返すことで、自己符号化器はデータの特徴を学習します。これは、何度も絵を写し取ることで、絵を描くのが上手になるのと同じです。小さくする際に、本当に必要な情報だけを残すことで、不要な情報や雑音が取り除かれます。例えば、人物の写真であれば、背景や細かいシワなどはなくなり、人物の顔や輪郭といった重要な特徴だけが抽出されます。これは、写真の不要な部分を消しゴムで消して、重要な部分だけを残すのと同じです。
そして、小さくなった情報から元の絵を再現しようと試みることで、重要な情報がどれだけ保持されているかを確認できます。もし、再現された絵が元の絵と大きく異なっている場合、重要な情報が失われているということになります。逆に、再現された絵が元の絵とほぼ同じであれば、重要な情報がしっかりと保持されているということになります。
自己符号化器は、この小さくする処理と元に戻す処理を繰り返すことで、データの本質的な特徴を捉える能力を向上させていきます。これは、職人が何度も同じ作業を繰り返すことで技術を磨くように、自己符号化器の精度を高めていくことに繋がります。
様々な応用事例

自己符号化器は、データの特徴を掴み、様々な形に変換する技術であり、多くの分野で活用されています。まるで、粘土をこねて様々な形を作るように、データという粘土を自己符号化器によって自由自在に操ることが可能です。
例えば、写真や絵といった画像を扱う場面を考えてみましょう。画像には、風景や人物といった主要な情報以外にも、細かい傷やノイズといった不要な情報が含まれていることがあります。自己符号化器は、画像データの中から主要な情報だけを抜き出し、ノイズを取り除くことができます。まるで、写真の修復作業のように、画像を綺麗に補正し、見やすくすることが可能です。また、画像に写っている物体を見分ける、いわゆる画像認識の分野でも活躍します。自己符号化器は、画像の特徴を掴むことで、猫や犬、車といった物体を識別する手助けをします。
機械の故障や不正アクセスといった異常を検知する場面でも、自己符号化器は力を発揮します。普段は正常に稼働している機械のデータを自己符号化器に学習させます。すると、機械に異常が発生した際に、普段とは異なるデータが出てくるため、それを異常として検知することが可能になります。これは、工場の機械の監視やネットワークセキュリティなど、様々な分野で応用されています。
さらに、自己符号化器は、大量のデータの中から重要な情報だけを抜き出し、整理することも得意です。膨大な量のデータは、そのままでは全体像を把握することが難しく、分析も困難です。自己符号化器を用いることで、データの持つ重要な特徴を保持したまま、データ量を減らすことができます。これは、データの全体像を掴みやすくし、分析を容易にすることに繋がります。
このように自己符号化器は、データを様々な用途に合わせて変換できる、非常に汎用性の高い技術と言えるでしょう。
| 活用分野 | 効果 |
|---|---|
| 画像処理 | ノイズ除去、画像補正、画像認識 |
| 異常検知 | 機械の故障検知、不正アクセス検知 |
| データ整理 | データの次元削減、データの可視化 |
教師なし学習の利点

教師なし学習とは、人間が正解を教えることなく、計算機が自らデータの背後にある隠れた法則やパターンを見つける学習方法です。まるで、ジグソーパズルを完成させるように、バラバラのピースであるデータから全体像を描き出す作業に似ています。この手法は、特に近年のデータ量の爆発的な増加に伴い、注目を集めています。
従来の教師あり学習では、一つ一つのデータに「これは猫」「これは犬」といった具合に正解ラベルを付ける必要がありました。このラベル付け作業は、大変な手間と時間がかかるため、大量のデータを扱う場合、大きな負担となっていました。教師なし学習の大きな利点は、このラベル付け作業が不要な点にあります。そのため、容易に大量のデータを用いて学習を進めることが可能です。
例えば、ある商品の購買履歴データがあるとします。教師あり学習では、それぞれの購買データに「この商品は売れる」「この商品は売れない」といったラベルを付ける必要があります。一方、教師なし学習では、ラベルを付けることなく、購買データから「この商品とこの商品は一緒に買われやすい」「この商品は特定の時期によく売れる」といった隠れた関係性を自動的に見つけることができます。
自己符号化器は、この教師なし学習を用いた代表的な技術の一つです。自己符号化器は、入力されたデータを一度圧縮し、その後再び元のデータに復元するように学習を行います。この学習過程で、データの本質的な特徴を捉える能力を獲得します。そして、大量のデータから重要な特徴を自動的に抽出し、データに潜む構造や関係性を明らかにすることで、私たち人間では気づくのが難しい隠れた知見の発見に役立ちます。これは、ビジネスにおける新たな戦略の立案や、科学研究における新たな発見につながる可能性を秘めています。
このように、教師なし学習は、データのラベル付け作業を省き、大量データの分析を効率化するだけでなく、データに潜む新たな価値の発見にも貢献する、大変将来性のある技術と言えるでしょう。
| 教師なし学習の特徴 | 詳細 | 例 |
|---|---|---|
| 正解ラベル不要 | ラベル付け作業が不要なため、大量のデータを容易に利用可能。 | 商品の購買履歴データから、関連性や売れる時期を自動的に発見。 |
| 自己符号化器 | 入力データを圧縮・復元する学習を通して、データの本質的な特徴を捉える。 | 大量のデータから重要な特徴を自動的に抽出。 |
| データの潜在価値発見 | 人間では気づきにくい隠れた知見の発見に役立つ。 | ビジネス戦略立案や科学研究の新たな発見。 |
| 将来性 | データ分析の効率化、新たな価値の発見に貢献する将来性のある技術。 | – |
今後の展望

自己符号化器は、これからの情報技術を支える重要な技術として、大きな発展が見込まれています。特に、深層学習と組み合わせることで、複雑なデータの構造をより深く理解し、これまで以上に精度の高い分析が可能になると期待されています。例えば、画像認識の分野では、より細かい特徴を捉えることで、ノイズや歪みに強い認識を実現できる可能性があります。また、自然言語処理の分野では、文章の意味をより正確に理解し、高精度な翻訳や要約を生成できるようになる可能性も秘めています。
さらに、自己符号化器の応用範囲は、様々な分野に広がることが予想されます。医療分野では、画像診断の精度向上や病気の早期発見に役立つことが期待されています。例えば、レントゲン写真やMRI画像から、医師の目では見つけにくい微細な異常を検出することで、早期の治療開始に繋げられる可能性があります。金融分野では、不正検知やリスク管理に活用することで、より安全な金融取引を実現できる可能性があります。顧客の取引履歴を分析し、通常とは異なるパターンを検知することで、不正行為を未然に防ぐことが期待されます。製造分野では、製品の品質管理や故障予測に活用することで、生産効率の向上やコスト削減に貢献できる可能性があります。センサーデータから製品の異常を早期に検知し、適切なメンテナンスを行うことで、大きな損失を防ぐことが期待されます。
このように、自己符号化器は、データの本質を捉えることで、様々な分野で革新をもたらす可能性を秘めています。今後の研究開発によって、さらに高性能な自己符号化器が登場し、私たちの社会をより豊かに、そしてより便利にする技術へと進化していくことでしょう。
| 分野 | 期待される効果 | 具体的な例 |
|---|---|---|
| 画像認識 | ノイズや歪みに強い高精度な認識 | より細かい特徴を捉える |
| 自然言語処理 | 高精度な翻訳や要約生成 | 文章の意味をより正確に理解 |
| 医療 | 画像診断の精度向上、病気の早期発見 | 医師の目では見つけにくい微細な異常を検出 |
| 金融 | 不正検知、リスク管理による安全な金融取引 | 顧客の取引履歴から通常とは異なるパターンを検知 |
| 製造 | 製品の品質管理、故障予測による生産効率向上、コスト削減 | センサーデータから製品の異常を早期に検知 |
まとめ

自己符号化器とは、データの特徴を自ら学習する人工知能技術です。まるで鏡のように、入力されたデータを一旦圧縮し、そして元の形に戻すことを繰り返すことで、データの持つ本質的な特徴を捉えることができます。この学習方法は、教師なし学習と呼ばれ、人間が正解を教える必要がありません。そのため、大量のデータからでも、効率的に学習を進めることが可能です。
自己符号化器は、様々な場面で活躍します。例えば、画像にノイズが含まれている場合、自己符号化器はそのノイズを取り除き、綺麗な画像を復元することができます。また、大量のデータの中から、通常とは異なる特徴を持つデータ、つまり異常値を見つけることも得意です。クレジットカードの不正利用の検知などに役立ちます。さらに、高次元のデータを低次元に圧縮することで、データの解析を容易にすることもできます。これは、膨大な量の遺伝子データなどを扱う際に特に有効です。
自己符号化器は、今後ますます発展していくと期待されています。医療分野では、画像診断の精度向上や新薬開発への応用が考えられます。製造業では、製品の品質管理や故障予測に役立つでしょう。また、金融分野では、市場予測やリスク管理に活用される可能性があります。このように、様々な分野での応用が期待され、私たちの生活をより便利で豊かなものにする可能性を秘めています。人工知能の発展を支える重要な技術として、自己符号化器は今後ますます注目を集めていくことでしょう。
| 項目 | 説明 |
|---|---|
| 定義 | データの特徴を自ら学習する人工知能技術。入力データを圧縮し、元の形に戻すことを繰り返すことで、データの本質的な特徴を捉える。 |
| 学習方法 | 教師なし学習 |
| メリット | 人間が正解を教える必要がなく、大量のデータから効率的に学習できる。 |
| 活用例 |
|
| 応用分野 |
|
| 将来展望 | 様々な分野での応用が期待され、生活をより便利で豊かにする可能性を秘めている。 |