
k-means法でデータを分類

デジタル化を知りたい
先生、k-means法って、どういうものですか?

デジタル化研究家
k-means法は、データの集まりをいくつかのグループに分ける方法だよ。最初にグループの数(k個)を決めて、グループの中心(重心)を適当に決める。そして、それぞれのデータがどの重心に近いかを計算して、近い重心のグループにデータを入れていくんだ。
デジタル化を知りたい
なるほど。中心を決めて、近いものをまとめていくんですね。すべてのデータ同士の距離を計算しなくていいんですよね?
デジタル化研究家
そうだね。k-means法では、データ間の距離をすべて計算する必要はないよ。それぞれのデータと、k個の重心との距離だけ計算すればいいので、計算の手間が省けるんだ。
k-means法とは。
データの分類方法の一つである『k-means法』について説明します。この方法は、まず最初に分類したいグループの数(これを『重心』の数と呼びます)を決め、その数だけ目印となる点をランダムに配置します。次に、それぞれのデータがどの目印に近いかを計算し、近いデータ同士を同じグループにまとめていきます。この作業を繰り返すことで、データがいくつかのグループに綺麗に分類されます。k-means法を使う利点は、データ同士の全ての距離を計算する必要がないため、計算の手間が省けることです。
はじめに

近ごろ、多くの情報を集めて調べることが大切になってきています。それに伴い、集めた情報から大切な事柄を見つけ出す技術が注目を集めています。特に、たくさんの情報を扱うときには、情報の持ち味に合わせてグループ分けすることで、全体の様子が分かりやすくなります。このような情報のグループ分けを「集団分け」と呼び、その方法の一つとして「K平均法」がよく使われています。
K平均法は、比較的簡単な手順で情報の分類ができるため、様々な分野で役立っています。例えば、顧客の購買行動を分析してグループ分けすることで、それぞれに合った販売戦略を立てることができます。また、医療分野では、患者の症状を基にグループ分けすることで、より効果的な治療法の開発に繋がることが期待されています。
K平均法は、まず初めにいくつのグループに分けるかを決めます。これを「K」という値で表します。そして、それぞれのグループの中心となる点を選びます。これらの点を「重心」と呼びます。次に、全ての情報を最も近い重心に割り当てます。全ての情報が割り当てられたら、それぞれのグループの重心を再計算します。これを繰り返すことで、重心の位置が少しずつ変わり、最終的にはそれぞれのグループの情報がなるべく均等になるように配置されます。
K平均法は計算の手間が少なく、結果が分かりやすいという利点がありますが、最初にグループの数を決める必要があるため、適切なK値を選ぶことが重要になります。K値が小さすぎると、異なる性質の情報が同じグループに分類されてしまう可能性があり、大きすぎると、似た性質の情報が異なるグループに分けられてしまう可能性があります。そのため、K値を調整しながら分析を行うことが必要です。K平均法を理解し、適切に活用することで、情報分析の可能性を広げ、より深い理解に繋げることができるでしょう。
| 項目 | 内容 |
|---|---|
| 手法 | K平均法 |
| 目的 | 大量の情報をグループ分けし、全体の様子を分かりやすくする。 |
| 手順 | 1. グループの数(K)を決める。 2. 各グループの重心を選ぶ。 3. 全ての情報を最も近い重心に割り当てる。 4. 各グループの重心を再計算する。 5. 3と4を繰り返す。 |
| 利点 | 計算の手間が少ない。 結果が分かりやすい。 |
| 欠点/注意点 | 適切なK値を選ぶ必要がある。 K値が小さすぎると、異なる性質の情報が同じグループに分類される可能性がある。 K値が大きすぎると、似た性質の情報が異なるグループに分けられてしまう可能性がある。 |
| 応用例 | 顧客の購買行動分析 医療における治療法開発 |
手法の仕組み

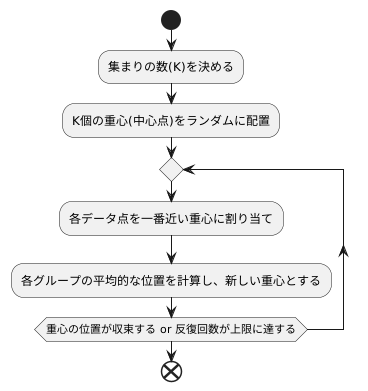
この手法は、データをいくつかの集まりに分ける方法で、集まりの数を最初に決めておく必要があります。たとえば、顧客データを5つのグループに分けたい場合、最初に5つのグループの中心点をランダムに決めます。この中心点を重心と呼びます。
次に、個々の顧客データが、どの重心に一番近いかを計算します。そして、一番近い重心に属するグループに、その顧客データを割り当てます。たとえば、ある顧客データが1番目の重心に一番近ければ、その顧客データは1番目のグループに属することになります。
全ての顧客データをグループに割り当て終わったら、各グループに属する顧客データの平均的な位置を計算し、それを新しい重心とします。
その後、また個々の顧客データが、新しい重心のどれに一番近いかを計算し、一番近い重心に属するグループに割り当て直します。そして、また各グループの平均的な位置を計算して、重心を更新します。
このように、重心の位置を計算し直し、顧客データのグループ分けを繰り返すことで、次第に重心の位置が適切な場所に移動し、顧客データが最適なグループに分けられていきます。
この繰り返し作業は、重心の位置がほとんど動かなくなったり、あらかじめ決めた回数繰り返した時点で終了します。これにより、最終的に顧客データがきれいにグループ分けされた状態になります。
手法の利点

分け方の良いところを見てみましょう。このやり方は、計算の手間が少なく済むのが大きな特徴です。データの集まりと中心となる点との間の距離を測る計算は、単純な計算で済むので、たくさんのデータをとても効率良く処理できます。膨大な資料の山を分類する必要がある場合でも、このやり方なら速やかに結果を得ることができます。
さらに、グループの数を自由に決めることができるのも利点です。例えば、顧客を購買傾向で3つのグループに分けて分析したい場合や、商品の特性で5つのグループに分けて管理したい場合など、分析の目的に合わせて自由にグループ数を調整できます。目的や状況に応じて柔軟に対応できるため、様々な場面で役立ちます。
また、仕組み自体がとても単純なので、簡単にプログラムに組み込むことができます。多くの統計処理の道具や readily available な部品集で利用できるため、手軽に試すことができます。専門的な知識がなくても比較的容易に使いこなせるため、データ分析の入門に最適です。慣れない人でも安心して利用できます。
このように、計算が楽で、グループ数を自由に決められて、使いやすいという多くの利点を持つこの手法は、データ分析の最初のステップとして最適と言えるでしょう。誰でも気軽に使い始めることができ、データ分析の面白さを体験するのに最適な方法です。まずはこの方法から始めて、データ分析の世界に触れてみてはいかがでしょうか。
| メリット | 説明 |
|---|---|
| 計算の手間が少ない | データと中心点との距離計算が単純で、大量データを効率良く処理できる |
| グループ数を自由に決められる | 分析の目的に合わせて、顧客の購買傾向や商品の特性などで自由にグループ数を調整できる |
| 簡単にプログラムに組み込める | 多くの統計処理ツールや部品集で利用でき、手軽に試せる |
| 使いやすい | 専門知識がなくても比較的容易に使いこなせる |
手法の欠点

集団分けの手法には、いくつか弱点があります。まず、集団の数を前もって決めておく必要があるため、最適な集団数がわからないときは、何度もやり直して探る必要が出てきます。
たとえば、顧客を購買行動でいくつかの集団に分けたい場合、あらかじめ集団の数を3つと決めて計算を始めます。しかし、計算が終わってみると、2つの集団に分けたり、4つの集団に分けたりする方が、顧客の購買行動の実態に合っていることがわかるかもしれません。その場合は、集団の数を3から2や4に変えて、もう一度計算をやり直すことになります。
また、計算の出発点となる中心の位置によって、結果が変わってくることがあります。同じデータで計算しても、出発点が違うと、最終的に出来上がる集団の形が変わってしまうことがあります。そのため、必ずしも一番良い分け方ができるとは限りません。
さらに、データの散らばり方によっては、うまく集団分けができないこともあります。たとえば、集団の形が複雑だったり、集団の大きさが大きく違っていたりする場合は、この手法ではうまく分けられないことがあります。
例えば、ある商品の購入者を年齢で3つの集団に分けようとした場合を考えてみましょう。もし、購入者の年齢層が、20代前半に集中していて、その他は40代と60代に少しだけ散らばっているような状況だと、うまく3つの集団に分けられない可能性があります。
このような場合は、他の集団分けの手法を検討する必要があります。色々な手法を試してみて、データの特性に合った手法を選ぶことが大切です。
| 集団分け手法の弱点 | 詳細 | 例 |
|---|---|---|
| 集団の数を事前に決定する必要がある | 最適な集団数が不明な場合、試行錯誤が必要。 | 顧客の購買行動による集団分けで、3つの集団と仮定して計算後、2つまたは4つの方が適切な場合、再計算が必要。 |
| 計算の出発点に依存する | 同じデータでも、出発点の違いにより結果が変わる。 | – |
| 最適な分け方ができるとは限らない | データの散らばり方によっては、うまく集団分けができない。 | – |
| データの散らばり方に影響される | 集団の形が複雑、集団の大きさにばらつきがある場合、うまく分けられない。 | 商品の購入者を年齢で3集団に分けようとした際、購入者の年齢層が20代前半に集中し、40代と60代に少し散らばっている場合、うまく分けられない可能性がある。 |
| 他の手法の検討が必要な場合がある | データの特性に合った手法を選ぶことが重要。 | – |
活用事例

多くの分野で活用されている「集団分け手法」は、データの集団を見つける強力な手法であり、様々な場面で役立っています。
例えば、販売促進の分野では、顧客をいくつかの集団に分けることで、それぞれの集団に合わせた販売戦略を立てることができます。過去の買い物履歴や顧客の属性情報といったデータに基づいて集団分けを行うことで、それぞれの集団に合わせた効果的な販売促進活動が可能になります。例えば、若者向けの商品を好む集団には、流行の広告媒体を通じて新商品情報を発信する一方、高価格帯の商品を好む集団には、会員限定の特別な催し物を案内するといった具合です。
また、画像の解析においても、「集団分け手法」は力を発揮します。画像を構成する小さな点それぞれをデータとして捉え、色の近い点をまとめて集団とすることで、画像の中から特定の領域を切り出したり、重要な特徴を掴むことができます。例えば、青空を背景に赤い花が咲いている写真であれば、青い点の集団と赤い点の集団を区別することで、空と花を別々に認識し、花の形状や大きさといった特徴を抽出することができるのです。
さらに、「集団分け手法」は、普段とは異なるデータ、いわゆる異常値を見つけるのにも役立ちます。過去のデータから得られた通常の集団から大きく外れたデータは、異常値として認識されます。例えば、工場の機械の稼働状況を監視している際に、普段とは異なる電力消費量のデータが検出された場合、「集団分け手法」を用いることで、それを異常値として捉え、機械の故障予兆を早期に発見することが可能になります。このように、「集団分け手法」は、多様な活用方法を持つ、非常に汎用性の高い手法と言えるでしょう。
| 分野 | 活用例 | 効果 |
|---|---|---|
| 販売促進 | 顧客を購買履歴や属性情報で集団分け | 集団ごとの効果的な販売戦略立案 |
| 画像解析 | 画像の構成点を色の近さで集団分け | 特定領域の切り出し、特徴抽出 |
| 異常検知 | 普段とは異なる電力消費量などのデータを検出 | 故障予兆の早期発見 |
まとめ

集まりを作るやり方の一つとして、ケーミーンズ法というものがあります。これは、複雑な計算を必要とせず、比較的簡単に使える方法なので、様々なデータの分析で使われています。この方法を使うと、バラバラになっているデータの中から、似た性質を持つものをグループ分けすることができます。
ケーミーンズ法を使うことのメリットはたくさんあります。まず、計算の手順が分かりやすく、コンピュータで計算させやすいという点です。また、大量のデータを扱う場合でも、比較的速く結果を得ることができます。さらに、得られたグループ分けの結果を、図などを使って視覚的に分かりやすく示すことも可能です。これらの利点から、ケーミーンズ法は、顧客の分類や商品の推奨など、ビジネスの現場でも広く活用されています。
しかし、ケーミーンズ法にはいくつか弱点もあります。例えば、あらかじめいくつのグループに分けるかを決めておく必要がありますが、適切なグループの数を事前に知ることは難しい場合が多いです。また、データの性質によっては、うまくグループ分けできないこともあります。特に、グループの形が複雑な場合や、グループの大きさが大きく異なる場合には、ケーミーンズ法は適していないことがあります。さらに、外れ値と呼ばれる、他のデータから大きく離れた値に影響されやすいという欠点もあります。
そのため、ケーミーンズ法を使う際には、データの性質をよく理解しておくことが重要です。例えば、データの中に外れ値が含まれている場合は、あらかじめそれらを取り除くなどの処理が必要です。また、グループの数を変えて試してみることで、より適切な結果を得られる可能性があります。ケーミーンズ法は便利な方法ですが、万能ではありません。他のグループ分けの方法も検討し、データの特性に合った最適な方法を選ぶことが大切です。データ分析の手法は日々進歩しており、ケーミーンズ法も今後さらに発展していくことが期待されます。
| 項目 | 内容 |
|---|---|
| 手法 | ケーミーンズ法 |
| 説明 | 複雑な計算を必要とせず、似た性質を持つデータをグループ分けする手法。 |
| メリット |
|
| デメリット |
|
| 注意点 |
|
| 将来展望 | 今後さらに発展していくことが期待される。 |