
名寄せエンジンでデータ活用を加速

デジタル化を知りたい
先生、「名寄せエンジン」って一体何ですか? リストの重複率を計算するってどういうことでしょうか?

デジタル化研究家
そうだね。「名寄せエンジン」とは、例えば顧客リストのように、たくさんのデータの中に同じ人が複数の名前で登録されている場合、それを探し出して一つにまとめるための仕組みだよ。同じ住所や電話番号の情報から、同一人物の可能性が高い人を探し出すんだ。
デジタル化を知りたい
なるほど。でも、同じ名前の人もいるかもしれませんよね?その場合はどうするんですか?
デジタル化研究家
いい質問だね。名前が同じでも、住所や電話番号、生年月日などの情報が異なれば、別人だと判断する。複数の情報を組み合わせて、重複しているかどうかを確率で判断するんだ。その確率のことを重複率と呼ぶんだよ。
名寄せエンジンとは。
重複した情報を取り除いて、整理する仕組みについて説明します。これは、複数のリストにある項目を比べることで、同じ内容のものがどのくらいあるかを計算するものです。
はじめに

昨今、情報技術の進歩に伴い、企業活動において様々な情報が電子的に蓄積され、膨大な量の資料が集まるようになりました。これらの資料をうまく活用することで、企業は新たな価値を生み出し、競争力を高めることができます。しかし、資料の質が良くなければ、せっかくの資料も宝の持ち腐れとなってしまいます。質の良い資料とは、正確で矛盾がなく、整理された状態の資料を指します。
現実には、同じ顧客や商品に関する情報が、会社の様々な場所に散らばっていることがよくあります。例えば、営業部が持つ顧客情報と、顧客管理部が持つ顧客情報が別々に管理され、内容が食い違っているといったケースです。また、同じ顧客なのに、名前の表記が違っていたり、住所が古くなっていたりすることもあります。このような情報の重複や不整合は、業務の非効率化を招きます。例えば、同じ顧客に何度も営業をかけてしまったり、誤った情報に基づいて顧客対応をしてしまったりする可能性があります。また、経営判断にも悪影響を及ぼす可能性があります。例えば、顧客の購買動向を正しく把握できず、効果的な販売戦略を立てられないといった事態も起こりえます。
こうした問題を解決するために、情報の重複を取り除き、正確な情報を一か所にまとめて管理する技術が重要になってきています。この技術の一つとして、「名寄せエンジン」と呼ばれるものがあります。名寄せエンジンは、様々な場所に散らばっている情報を照合し、同一のものを探し出す技術です。例えば、表記が違っている顧客情報でも、名寄せエンジンを使うことで、同じ顧客の情報であることを自動的に判断し、一つにまとめることができます。これにより、情報の正確性と一貫性を確保し、業務効率の向上や顧客満足度の向上、そして的確な経営判断につなげることが可能になります。
| 問題点 | 原因 | 解決策 |
|---|---|---|
| 資料の質が悪い(不正確、矛盾、整理不足) | 情報の重複、不整合(例:顧客情報の食い違い、表記の揺れ、古い情報) | 情報の重複を取り除き、正確な情報を一元管理(例:名寄せエンジン) |
| 業務の非効率化(例:重複営業、誤った顧客対応) | 情報の重複、不整合 | 情報の重複を取り除き、正確な情報を一元管理 |
| 経営判断への悪影響(例:顧客購買動向の把握不足) | 情報の重複、不整合 | 情報の重複を取り除き、正確な情報を一元管理 |
名寄せエンジンの仕組み

名寄せエンジンは、複数のデータ群の中から、同一のものを指し示す重複したデータを識別し、まとめるための仕組みです。 これは、まるで散らばったパズルのピースの中から同じ絵柄を見つける作業に似ています。
この作業を効率的に行うために、様々な方法が用いられます。まず、それぞれのデータが持つ属性情報、例えば名前、住所、電話番号などを比較します。これらの情報が完全に一致している場合は、同一データである可能性が非常に高いと判断できます。
しかし、現実のデータは書き間違いや表記の揺れを含んでいることが多く、単純な一致検索だけでは不十分です。そこで、「あいまい検索」という技術が役立ちます。これは、多少の文字の違いを許容して類似性を判断する技術で、「山田太郎」と「山田 たろう」のように、全角・半角の違いやスペースの有無などを無視して同一人物の可能性を探ることができます。
さらに、音声認識技術を応用することで、発音に基づいた名寄せも可能になります。例えば、データベースに登録されている名前の読み仮名と、入力された音声データの読み仮名を比較することで、表記が大きく異なる場合でも同一人物を特定できます。
近年では、機械学習も名寄せエンジンの精度向上に貢献しています。過去のデータから学習することで、複雑な表記の揺れや略称、異字体などにも対応できるようになり、より高度な名寄せを実現します。
名寄せエンジンは、これらの技術を組み合わせることで、膨大なデータの中から重複データを効率的に特定し、データの整理、分析の精度向上に役立ちます。これにより、顧客情報の管理やマーケティング活動の効率化など、様々な場面で効果を発揮します。

名寄せエンジンの活用例

名前をまとめる仕組みは、様々な場面で役に立ちます。
例えば、お客さまの情報を管理する仕組みに活用すると、同じお客さまの情報が重複して記録されるのを防ぐことができます。これまで、同じお客さまなのに、複数の名前で記録されていたために、全体を把握しにくかったり、それぞれに個別の案内を送ってしまったりするなどの問題がありました。名前をまとめる仕組みを使うことで、お客さま一人ひとりの情報を正確に把握し、より適切なご案内やサービスを提供できるようになります。
商品の情報を管理する仕組みにも役立ちます。同じ商品なのに、名前や登録の仕方が少し違うだけで、別の商品として記録されてしまうと、在庫の数が正しく把握できなかったり、発注ミスにつながったりする恐れがあります。名前をまとめる仕組みを導入することで、同じ商品は一つにまとめて管理できるようになり、在庫管理の効率を高め、無駄なコストを削減することができます。
医療の分野でも、この仕組みは大きな効果を発揮します。病院では、患者さんの情報は非常に重要です。もし、同じ患者さんなのに、異なる名前で記録されていたら、過去の診療情報が正しく引き継げず、誤った治療につながる危険性があります。名前をまとめる仕組みを使うことで、患者さんの情報を正確につなぎ合わせ、安全で的確な医療を提供することに貢献します。
このように、名前をまとめる仕組みは、様々な分野で情報の整理、正確性の向上、作業の効率化に役立ち、質の高いサービス提供を支える重要な技術となっています。
| 分野 | 効果 | 課題 |
|---|---|---|
| 顧客管理 | 顧客一人ひとりの情報を正確に把握し、適切な案内やサービス提供が可能 | 同一顧客の重複登録による情報の散在、個別案内の重複送付 |
| 商品管理 | 同一商品をまとめて管理、在庫管理の効率化、コスト削減 | 商品名の表記揺れによる重複登録、在庫数の不正確な把握、発注ミス |
| 医療 | 患者情報の正確な連携、安全で的確な医療提供 | 同一患者の複数登録による診療情報の断絶、誤った治療のリスク |
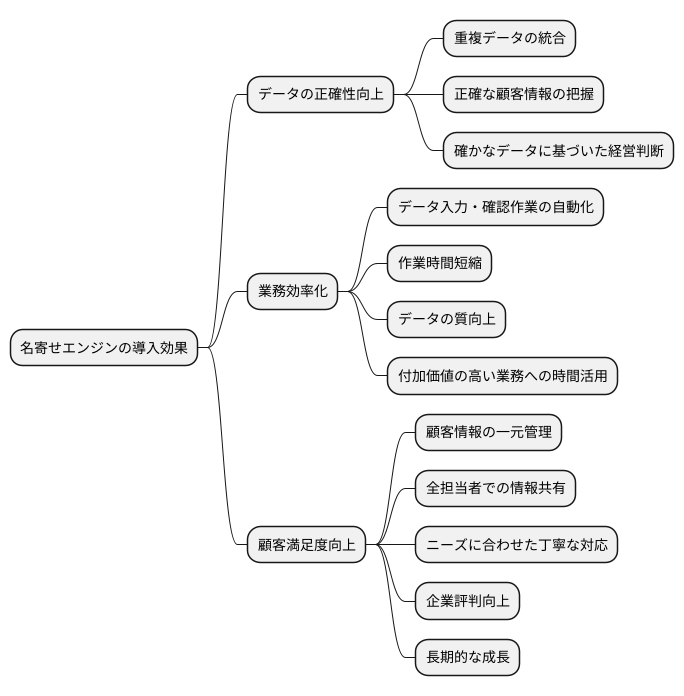
名寄せエンジンの導入効果

顧客一人ひとりの情報を正確に把握することは、現代の企業活動において非常に重要です。それを実現する手段として、名寄せエンジンが注目を集めています。名寄せエンジンとは、表記の揺れや入力ミスなどで重複して登録された顧客情報を、同一人物の情報としてまとめる仕組みです。この技術を導入することで、企業活動に様々な良い効果が生まれます。
まず、これまで別々のデータとして扱われていた重複情報が一つにまとめられることで、データの正確さが向上します。例えば、同じ顧客が複数の名前や住所で登録されていた場合、これまで別々の顧客として扱われていたため、全体像を把握することが困難でした。名寄せエンジンによってこれらの情報を統合することで、顧客一人ひとりの正確な情報を把握できるようになります。これにより、より確かなデータに基づいた経営判断や販売戦略の立案が可能になります。
次に、名寄せエンジンは、日々の業務の効率化にも大きく貢献します。これまで担当者が手作業で行っていたデータの入力や確認作業を自動化できるため、作業時間の大幅な短縮につながります。また、入力ミスや重複登録を未然に防ぐことができるため、データの質の向上にもつながります。空いた時間をより付加価値の高い業務に充てることで、生産性の向上も期待できます。
さらに、顧客情報の一元管理は、顧客対応の質の向上にもつながります。これまで部署ごとにバラバラに管理されていた顧客情報を一元管理することで、顧客一人ひとりの購買履歴や問い合わせ内容などを、全ての担当者が共有できるようになります。これにより、顧客のニーズに合わせた丁寧な対応が可能となり、顧客満足度の向上につながります。顧客満足度の向上は、企業の評判を高め、長期的な成長にも貢献します。
このように、名寄せエンジンの導入は、データの正確性向上、業務効率化、顧客満足度向上など、多岐にわたる効果をもたらします。これらの効果は、企業の競争力を高め、持続的な成長を支える重要な要素となるでしょう。
名寄せエンジンの選定

情報を整理するとき、同じものを一つにまとめる作業は「名寄せ」と呼ばれ、膨大な情報を扱う現代社会では、コンピューターを使って自動的に行う「名寄せエンジン」が欠かせません。この名寄せエンジンを選ぶ際には、幾つかの大切な点に注意する必要があります。
まず、どのような種類の情報をどれくらいの量扱うのか、どの程度の正確さを求めるのかをはっきりさせることが重要です。例えば、顧客情報のように重要なデータは高い精度が求められますが、そうでないデータは多少の誤差があっても許容できる場合があります。扱うデータの量も、処理速度に大きく影響するため、事前に見積もっておく必要があります。
次に、既に使用している仕組みに、新しく導入する名寄せエンジンがうまく繋がるかどうかを確認する必要があります。繋ぎ込み作業が複雑で時間と費用がかかる場合、導入自体が難しくなる可能性があります。また、導入にかかる費用だけでなく、使い続けるための費用も考慮しなければなりません。
さらに、将来、扱うデータが増えたり、機能を追加したりする際に、柔軟に対応できるかどうかも重要な点です。データ量の増加や新たな機能への要望に対応できない場合、再び別のエンジンを選定し直す必要が生じる可能性があります。
これらの点を総合的に判断し、自社の状況に最適な名寄せエンジンを選ぶことが、情報の整理、活用を成功させる鍵となります。最適な名寄せエンジンは、業務の効率化を促し、企業の成長を大きく後押しするでしょう。
| 選定基準 | 詳細 |
|---|---|
| データの種類と量 | 扱う情報の種類、量を明確にする |
| 精度のレベル | 必要な精度のレベルを明確にする(例:顧客情報のような重要なデータは高い精度が必要) |
| 既存システムとの連携 | 既存システムとの連携の可否、容易性を確認する |
| コスト | 導入コストだけでなく、運用コストも考慮する |
| 拡張性/柔軟性 | 将来的なデータ増加や機能追加に対応できるか確認する |
今後の展望

情報を整理統合する技術は、これからますます発展していくでしょう。人工知能や、自ら学ぶ計算機の技術が進歩することで、情報を正確に結びつける能力がより高まり、もっと複雑な情報にも対応できるようになると考えられます。
加えて、必要な時に必要なだけ計算機の機能を借りる仕組みとの連携が強化され、もっと手軽に情報を結びつける道具を使えるようになることが期待されます。たとえば、これまでは自社で大きな計算機を持つ必要がありましたが、インターネットを通じて必要な時にだけ計算機の機能を借り、情報を結びつける作業を行うことができるようになります。これにより、情報整理にかかる費用や時間を大幅に削減できるでしょう。
さらに、個人の情報を適切に取り扱うという観点からも、安全性を保ちつつ情報を結びつける技術開発が進むと考えられます。個人情報保護の重要性が高まる中で、情報を結びつける際には、個人のプライバシーを侵害しないように十分な配慮が必要となります。そのため、匿名化技術や暗号化技術などを活用し、安全に情報を管理しながら結びつける技術が求められています。
情報を整理統合する道具は、情報を有効に活用するための土台となる技術として、企業の業務を計算機などを活用した仕組みに変えていく上で、ますます重要な役割を担うでしょう。情報を整理統合することで、これまで見えていなかった関係性や傾向を発見し、新しい商品やサービスの開発、業務の効率化などに役立てることができます。これにより、企業は競争力を高め、持続的な成長を実現できるようになります。
| 技術の進歩 | メリット | 今後の展望 |
|---|---|---|
| 人工知能、機械学習 |
|
手軽な情報結合ツールの普及 |
| クラウドコンピューティング |
|
自社保有の計算機不要に |
| 匿名化技術、暗号化技術 |
|
プライバシー保護の強化 |
| 情報整理統合ツール |
|
企業のDX推進、競争力向上 |