
基盤モデル:未来を築く土台

デジタル化を知りたい
先生、『基盤モデル』って最近よく聞くんですけど、何のことか教えてください。

デジタル化研究家
簡単に言うと、たくさんの情報を学んで、色々な仕事ができる賢い道具のようなものだよ。 例えば、色々な種類の文章をたくさん読んで学習することで、文章の要約や翻訳、質問応答など、色々なことができるようになるんだ。
デジタル化を知りたい
色々な仕事に使えるっていうのは便利ですね!でも、どうやって色々なことができるようになるんですか?
デジタル化研究家
まず、膨大なデータで基本的なことを学習する段階と、その後、特定の仕事ができるように追加で学習する段階の二段階で学習するんだよ。 例えば、翻訳の仕事をさせたいなら、基本的な学習が終わった後に、たくさんの翻訳例を使って追加で学習させるんだ。そうすることで、翻訳が上手になるんだよ。
基盤モデルとは。
たくさんの情報を使って学習させた、色々な仕事に役立つコンピューターの仕組みのことです。まず、膨大な量のデータで基礎的な学習をさせ、その後、具体的な仕事に合わせて追加で学習させるという二段階の手順で作られます。この仕組みは『基盤モデル』と呼ばれ、世の中のデジタル化を進める上で重要な技術の一つです。
基盤モデルとは

膨大な量の情報を基に学習させた、いわば万能型の学習モデルのことを基盤モデルと呼びます。例えるならば、様々な料理の土台となる「だし」のようなものです。特定の料理を作る際に、だしに味付けをして調整するように、基盤モデルも様々な用途に合わせて追加で学習させることで、多様な作業に対応できます。
この追加学習は、専門的には「微調整」と呼ばれ、比較的少量の情報でモデルを特定の作業に特化させることができます。そのため、初めからモデルを学習させるよりも効率的に、高性能なモデルを構築することが可能になります。
基盤モデルは、大量の情報と計算能力を使って学習させるため、開発には高度な技術と費用が欠かせません。しかし、一度開発されると、様々な分野で応用できるため、費用対効果は高くなります。例えば、文章の理解や生成、翻訳、音声認識、画像認識など、多岐にわたる分野で活用が期待されています。
基盤モデルを使うことで、個々の企業や組織は、自前で高性能なモデルを開発する必要がなくなり、開発コストや時間を大幅に削減できます。また、基盤モデルは、最先端の技術を誰でも利用できるようにすることで、技術の民主化にも貢献します。
一方で、基盤モデルの開発や利用には、倫理的な問題や社会的な影響も考慮する必要があります。例えば、学習データに偏見が含まれている場合、モデルも偏った結果を出力する可能性があります。また、悪意のある利用を防ぐための対策も重要です。今後、基盤モデルは様々な技術革新の基盤となることが期待されるため、技術的な発展と同時に、倫理的な側面や社会的な影響についても継続的な議論が必要です。
| 基盤モデルの特徴 | メリット | デメリット |
|---|---|---|
| 膨大な情報に基づいて学習した万能型モデル(様々な料理の「だし」のようなもの) 追加学習(微調整)で特定の作業に特化可能 |
効率的かつ高性能なモデル構築が可能 様々な分野での応用が可能(文章理解、生成、翻訳、音声認識、画像認識など) 開発コスト・時間の削減 技術の民主化 |
開発に高度な技術と費用が必要 倫理的な問題(学習データの偏見) 悪意のある利用の可能性 |
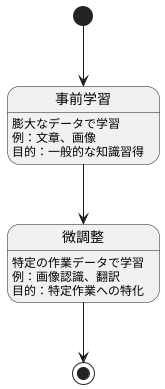
基盤モデルの学習方法

基盤モデルを学習させる方法は、大きく二つの段階に分かれています。最初の段階は「事前学習」と呼ばれ、いわばモデルの基礎を作る段階です。インターネット上に公開されている膨大な量の文章や画像といったデータを使って、モデルに一般的な知識を習得させます。この段階では、特定の用途を定めずに、様々なデータに触れさせることで、言葉の意味や画像の特徴といった、広く役立つ基本的な能力を身につけさせます。例えば、大量の文章を読み込ませることで、言葉の繋がりや文法、言葉が持つ意味などを学習させ、画像データを読み込ませることで、物の形や色、模様といった視覚的な特徴を学習させます。この事前学習は、非常に多くの計算資源と時間を必要とする大規模な処理です。
次の段階は「微調整」と呼ばれ、特定の作業に特化してモデルの能力を高める段階です。事前学習で培った基礎能力を土台に、特定の目的のために追加で学習を行います。例えば、画像認識に特化させたい場合は、あらかじめ用途を分類した画像データを使って追加学習を行います。翻訳作業に特化させたい場合は、複数の言語で書かれた同じ意味の文章を大量に学習させます。この微調整によって、モデルは特定の作業に最適化され、高い性能を発揮できるようになります。例えるなら、事前学習で様々な分野の一般常識を身につけた人材を、微調整によって特定の職務に精通した専門家へと育成するようなものです。この二段階の学習方法によって、基盤モデルは無駄なく様々な作業に適応できるようになります。まるで人間の学習過程のように、まず広く浅く知識を蓄え、その後、特定の分野を深く学ぶことで、専門性を高めていくのです。
基盤モデルの利点

基盤モデルは、様々な利点を持つ革新的な技術です。まず、一つのモデルを多様な用途に転用できる汎用性の高さが挙げられます。従来の人工知能開発では、個々の課題に合わせて専用のモデルを一から作る必要がありました。しかし、基盤モデルは大量のデータで事前に学習済みのため、画像認識や文章生成、音声処理など、多様な作業に適応させることができます。このため、個別にモデルを開発する時間や費用を大幅に抑えられます。また、従来の手法では、高精度な結果を得るには大量の学習データが必要でした。しかし、基盤モデルは既に膨大なデータで学習済みなので、比較的少ないデータ量でも高い精度を実現できる可能性があります。これは、データ収集が難しい分野や、新しい分野への応用において大きな強みとなります。さらに、専門家でなくても比較的簡単に利用できるという利点もあります。これまで人工知能技術の活用には、高度な専門知識やプログラミング技術が必要でした。しかし、基盤モデルは使いやすいツールやインターフェースが提供されているため、専門知識を持たない人でも容易に利用できます。これにより、人工知能技術がより多くの人々に利用され、様々な分野で革新が生まれることが期待されます。例えば、高度な画像編集ソフトの操作方法を知らなくても、基盤モデルを利用することで、簡単な指示で高品質な画像編集作業を行うことができます。また、プログラミングの知識がなくても、基盤モデルを使って文章の自動生成や要約、翻訳などを容易に行うことができます。このように基盤モデルは、人工知能技術の敷居を下げ、より多くの人々がその恩恵を受けられるようにする可能性を秘めています。今後、様々な分野への応用が期待され、社会全体に大きな変化をもたらす可能性があります。
| 基盤モデルの利点 | 説明 |
|---|---|
| 汎用性の高さ | 一つのモデルを画像認識、文章生成、音声処理など多様な用途に転用できる。個別にモデルを開発する時間や費用を大幅に削減。 |
| 少ないデータ量での高精度 | 既に膨大なデータで学習済みのため、比較的少ないデータ量でも高い精度を実現できる可能性がある。データ収集が難しい分野や、新しい分野への応用において大きな強み。 |
| 利用の容易さ | 使いやすいツールやインターフェースが提供され、専門知識を持たない人でも容易に利用できる。人工知能技術の敷居を下げ、より多くの人々が恩恵を受けられる可能性。 |
基盤モデルの課題

基盤モデルは様々な分野で革新をもたらす可能性を秘めていますが、同時にいくつかの重要な課題も抱えています。まず、その開発には膨大な計算資源とデータが必要です。最新の計算機と大規模なデータセンターが必要となるため、多額の投資が可能な一部の大企業しか開発に参入できない可能性があります。これは、技術の寡占化につながり、技術革新の速度を落とす懸念があります。
次に、学習データの偏りは、モデルの出力結果にも偏りをもたらす可能性があります。例えば、特定の属性の人物に関するデータが学習データに多く含まれている場合、モデルはその属性を持つ人物に有利な結果を出力する可能性があります。これは公平性の観点から大きな問題であり、社会的な不平等を助長する可能性も懸念されます。そのため、偏りのない多様なデータを用いて学習させることが不可欠ですが、現実的には多様なデータを収集することは容易ではありません。
さらに、基盤モデルは非常に複雑な構造をしているため、出力結果がどのようにして導き出されたのかを説明することが困難です。これはモデルの透明性の欠如につながり、利用者にとってはその信頼性を損なう要因となります。例えば、医療診断支援に用いる場合、医師はなぜその診断結果が出力されたのかを理解できなければ、安心して利用することは難しいでしょう。また、誤った判断を下した際の責任の所在も不明確になるという問題もあります。
これらの課題を解決するためには、計算資源の効率化や、偏りのないデータ収集方法の確立、モデルの出力結果を説明可能な技術の開発など、多方面からのアプローチが必要です。産官学が連携し、これらの課題解決に向けて取り組むことで、基盤モデルはより安全で信頼性の高い技術として社会に貢献していくことができると考えられます。
| 課題 | 詳細 | 懸念 |
|---|---|---|
| 膨大な計算資源とデータ | 開発には最新の計算機と大規模なデータセンターが必要 | 技術の寡占化、技術革新の速度低下 |
| 学習データの偏り | 特定の属性の人物に関するデータが多い場合、モデルはその属性を持つ人物に有利な結果を出力する可能性 | 公平性の問題、社会的な不平等を助長 |
| 出力結果の説明困難性 | モデルの構造が複雑で、出力結果の導出過程を説明することが難しい | モデルの透明性の欠如、信頼性低下、責任所在の不明確化 |
基盤モデルの未来

今まさに発展を続けている基盤モデルという技術は、様々な可能性を秘めており、将来への影響力は計り知れません。膨大な量の情報を学習させることで、今よりもはるかに複雑な作業もこなせるようになると見られています。この技術が様々な分野で活用されるようになれば、私たちの暮らしはより豊かになり、便利になるでしょう。
例えば、医療の分野では、基盤モデルは病気の診断を助ける力となります。医師は基盤モデルを活用することで、より正確な診断を迅速に行えるようになるでしょう。また、教育の分野では、一人ひとりの学習状況に合わせた個別指導を実現するのに役立ちます。それぞれの理解度に合わせた教材や指導方法を提供することで、学習効果の向上に繋がるでしょう。さらに、製造業においては、製品の品質管理を向上させることができます。不良品の発生を抑え、より高品質な製品を安定して供給することが可能になるでしょう。
その他にも、基盤モデルは様々な分野で革新的な変化をもたらすと期待されています。例えば、農業分野では、農作物の生育状況を分析し、最適な栽培方法を提案することで収穫量の増加に貢献するでしょう。また、金融分野では、市場の動向を予測し、より効果的な投資戦略を立てるのに役立つでしょう。このように、基盤モデルは様々な産業を変革させ、社会全体に大きな影響を与える可能性を秘めています。
基盤モデルは、まさに未来社会を支える重要な基盤技術となるでしょう。今後の更なる発展に大いに期待が寄せられています。継続的な研究開発と、より多くの分野での活用を通して、基盤モデルは私たちの未来をより良いものへと形づくる力となるでしょう。
| 分野 | 基盤モデルの活用と効果 |
|---|---|
| 医療 | 病気の診断支援、迅速で正確な診断 |
| 教育 | 個別指導、学習効果の向上 |
| 製造業 | 品質管理向上、不良品発生抑制 |
| 農業 | 生育状況分析、収穫量増加 |
| 金融 | 市場動向予測、効果的な投資戦略 |
基盤モデルと社会

近年、急速に発展を遂げている基盤モデルは、私たちの社会に大きな変革をもたらす可能性を秘めています。この技術は、膨大な量の情報を学習し、様々なタスクを実行できる能力を持つことから、様々な分野への応用が期待されています。
例えば、自動運転技術への応用は、交通事故の減少や渋滞の緩和といった効果をもたらすと期待されています。また、ロボット技術への応用は、介護や家事といった分野での労働力不足の解消に貢献する可能性があります。さらに、製造業や農業など、様々な産業分野において、生産性向上や効率化に役立つことが期待されています。
基盤モデルは、新しい事業の創出にも貢献すると考えられています。例えば、今までにない革新的な製品やサービスの開発、新たな市場の開拓などが期待されます。また、医療や教育といった分野においても、個別最適化されたサービスの提供や、質の高い教育機会の提供に役立つと期待されます。さらに、気候変動や貧困といった社会問題の解決にも、基盤モデルを活用した取り組みが期待されています。
しかし、基盤モデルの発展は、新たな問題を生み出す可能性もあります。例えば、自動化の進展による雇用の減少や、人工知能による判断への依存による人間の思考力低下といった懸念があります。また、基盤モデルが持つ膨大な情報へのアクセス制限や、個人情報の保護といった倫理的な問題も議論していく必要があります。
基盤モデルの利点と欠点を正しく理解し、社会全体で議論を深めていくことが重要です。関係省庁や専門家、企業、そして市民が一体となり、ルール作りや制度設計に取り組む必要があります。基盤モデルを適切に活用することで、より良い社会を築いていくことができると信じています。
